
By Scott Rushing, Richard Russell, and Yunus Piperdy
Underwriting practices today are a world away from those commonplace 20 years ago, but the biggest evolution is yet to come.
Big Data will truly transform underwriting over the next decade. Harnessing new data sources using the latest artificial intelligence (AI), machine learning (ML), and deep learning (DL) techniques will radically change every aspect of the risk assessment process.
But AI also brings important threats: Deploying these new technologies without consideration of the commercial, risk, ethical, regulatory, and societal factors could have disastrous consequences. In this article, we look in-depth at how Big Data and its tools are changing underwriting.
Who will hold the underwriting pen?
Over the past several years, technological advances as well as the growing prominence of the field of data science have completely transformed the business models and the business value chain for many industries. In credit and banking, for example, the vast majority of transactions have been automated and can now be conducted online.[1] Indeed, the four most valuable companies in the world today—Amazon, Apple, Google, and Microsoft—have their foundations in technology and data science.
These colossi have risen due to a multitude of factors, but Big Data and analytics are the common denominators. Ultimately, the winners in almost any industry win by offering speed, user convenience, and lower costs. Today’s tech giants selling products and services online are succeeding because they have disrupted traditional pricing and distribution structures—and, in doing so, they are improving the customer journey.
For the insurance industry, which is seeking to improve user service and accessibility for both customers and companies, not holding the underwriting pen might prove problematic. Insurance professionals regard risk assessment as a core competence, and understandably might resist relinquishing control. But if it becomes possible to automate more underwriting processes using technological advances and data science, some insurers may seek to outsource portions, or perhaps all, of risk assessment to another party.
In much the same way credit scoring by specialist providers in the banking sector has transformed that industry, third-party assessors could significantly transform underwriting by automating processes. Specialist third-party risk assessment companies with tech know-how, for example, could automate the gathering, processing, and analysis of underwriting data. Also, reinsurers, which often assume a sizable share of each risk, may be well-placed to help automate underwriting.
Can intelligent machines outperform underwriters?
The exponential growth of available data, coupled with massive increases in computer processing power and the evolution of Big Data, are accelerating the ability of insurers to understand and quantify risk. With newer categories of digital data available to insurers, such as prescription histories, credit-based information, and clinical test results, and from novel sources such as wearables and electronic health records, underwriting may be on the cusp of a fully digital transformation.
Many insurers are already pursuing data- and digital-based opportunities to change not just how underwriting is done but also when, and who does it. Although it is unlikely machines will ever be able to think and act like underwriters, intelligent machine-based risk assessment tools have reached an advanced stage of development and might soon match or even outperform underwriters in assessing certain risks.
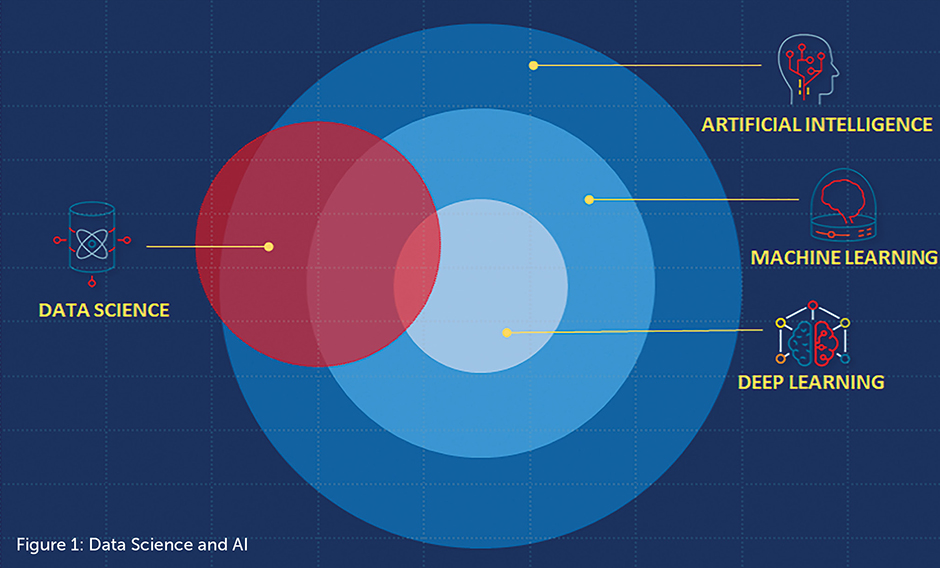
Artificial intelligence, machine learning, and deep learning
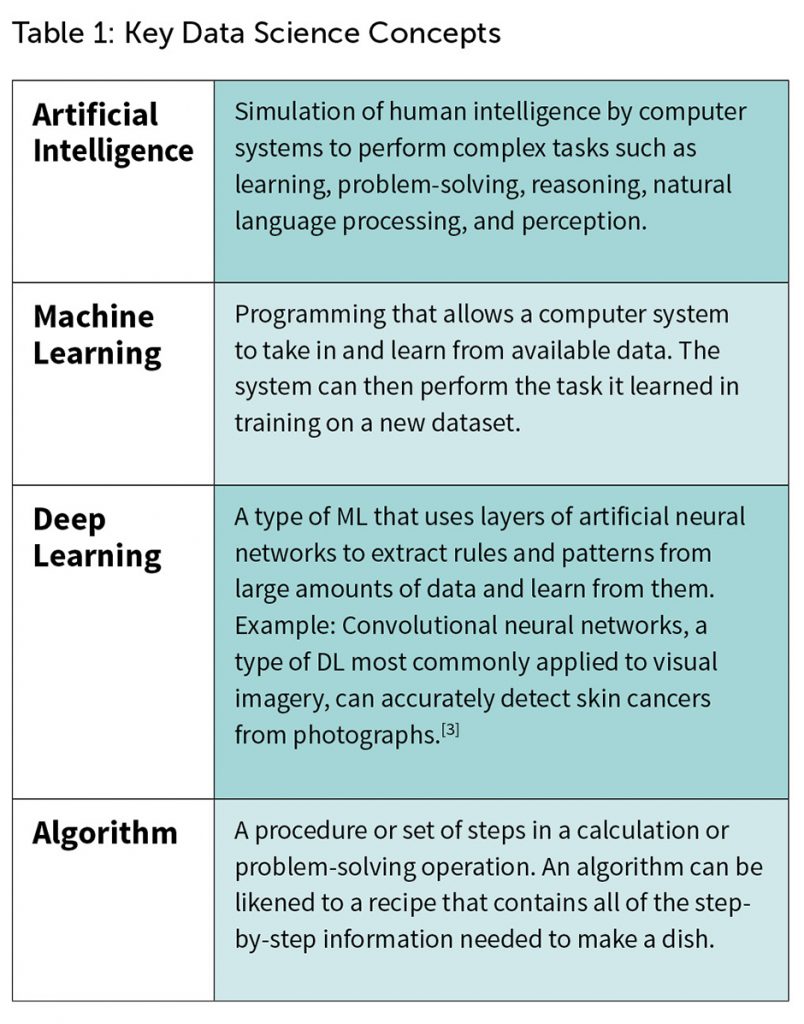
The terms artificial intelligence (AI), machine learning (ML), and deep learning (DL) are often used interchangeably, but they don’t all mean the same thing. AI, as the name suggests, can be defined as expert software systems that enable computers to perform tasks that have usually required human intelligence, such as learning, problem-solving, reasoning, natural language processing, and perception. AI has proven particularly powerful for visual perception, speech recognition, and language translation.[2]
AI is also the overarching concept that contains techniques and algorithms for realizing machine-based intelligence—namely ML and DL. ML algorithms enable machines to consume large datasets, learn from them, and then make accurate predictions by compiling and analyzing new datasets. DL, meanwhile, is a particular branch of ML that uses artificial neural networks, a type of expert system utilizing software that recognizes patterns and mimics how the human brain processes information.
AI technology can be classified as “narrow” or “general.” Narrow AI (also known as weak AI) focuses on specific tasks that are often rules-based and simple, with no actual “intelligence” required. General AI (also known as strong AI), on the other hand, focuses on applying solutions to complex problems with multiple variables. Some general AI systems may even be self-learning, using data to find patterns and update the system’s existing rules.
Some examples of how insurers are currently using AI include fraud detection (ML is good at uncovering anomalous patterns in a dataset), more accurate prediction of mortality risk, categorizing medical information from free text sources such as attending physician statements using natural language processing (NLP), and even reviewing a complete medical file—extracting pertinent data and then using it to make underwriting decisions.
Big Data’s underwriting impacts
The most obvious way in which Big Data has already influenced underwriting is in automated risk assessment. AI technologies such as NLP can help underwriters extract, filter, and summarize complex and detailed information.
AI can also improve underwriting by realizing the potential of Big Data to create efficiencies in process as well as analysis. New data sources can be the input that enable the development of novel rating factors as well as of systems that can perform underwriting triage and workflow case allocation.
The most significant impact of data science on underwriting, however, may be yet to come. As AI technology improves, it could radically disrupt the insurance application process—either by changing who can perform the underwriting or by allowing underwriting to be performed either earlier or later.
Automated risk assessment
Although automated risk assessment has its roots in rules-based expert systems going back to the 1990s, data science is transforming how automated underwriting is done. In its early days, underwriters used expert systems to facilitate jet-underwriting (i.e., to assess and quickly advance clean applications). As the programming of these systems expanded and improved, more sophisticated underwriting assessments occurred. Indeed, early expert systems contained tens of thousands of hard-coded underwriting rules that could assess medical, occupational, and avocational risks.
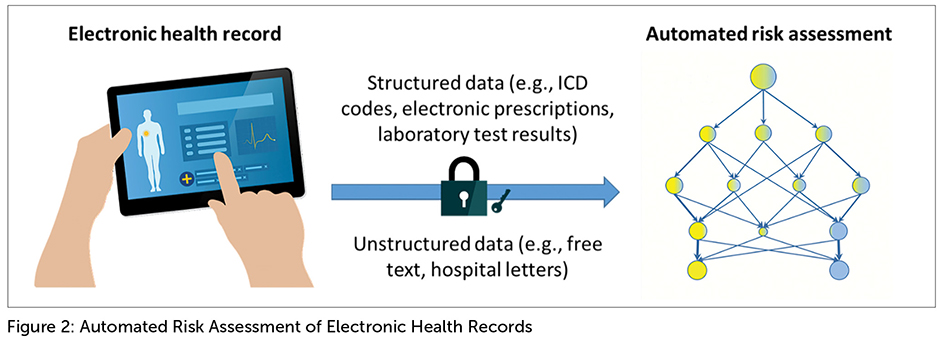
While expert systems still play an essential role in underwriting (and are likely to do so for many years to come), ML algorithms are enabling these systems to become better “trained” (i.e., be more effective) by letting them fine-tune underwriting rules and find new patterns of risk information. Big Data is also facilitating the development of expert systems that can utilize new data sources and deal with novel problems. For example, the availability of digitized medical reports such as electronic health records is enabling underwriting assessments of detailed and complex medical information to be more automated. Google and Apple are both highly interested in developing ways to leverage and monetize these new data sources.[4],[5],[6] Their efforts are still in early stages, but progress is likely to hasten as access to digitized data increases.
For cases involving complex medical histories where AI is not yet able to make the final underwriting decision, Big Data can still provide help via NLP and optical character recognition (OCR), both ML technologies. NLP and OCR can extract and filter essential information from hundreds of pages of medical reports and summarize it so systems can quickly and easily digest vital risk information, minimizing human error and saving underwriter time. The technology can also triage underwriting cases to improve new business workflow, enabling cases to be allocated by risk level and complexity to the most appropriate underwriting team members.
The growing availability of data also presents a major opportunity for underwriters to make more precise risk assessments, enabling individualized risk selection so that underwriting decisions can be tailored for each applicant. Real-world Big Data sources and ML technology can help underwriters accurately detect differences in risk profiles and strengthen a company’s underwriting philosophy by identifying novel rating factors or refining rating guidelines. Ultimately, significant improvements in underwriting accuracy will allow premiums to reflect each individual risk with greater precision. Whether or not the industry chooses to follow the path of more granular risk pools will require a careful consideration of the commercial, risk, ethical, regulatory, and societal factors.
When?
For more than a century, established practice has been to underwrite a case after an application is completed (whether on paper or online) and before a policy is issued. In recent years, however, a few insurers have begun to delay parts of the risk assessment process until a few weeks after the policy is issued. This process, called post-issue underwriting, lets an applicant be initially accepted based on readily available information in the application, subject to a more detailed assessment soon after the policy goes live. This approach has been found to appeal to consumers as the policy can be accepted earlier in the process. It is also attractive to insurers, as medical evidence costs are incurred only for applicants who actually buy the policy. Greater access to data, particularly electronic health records, also makes post-issue underwriting well-suited to new business accepted via accelerated underwriting programs.
In the near future, we might see insurers use post-issue underwriting more frequently. However, longer term it may also be possible to conduct much of the underwriting assessment process at the point of sale. Future consumers could be more likely to have immediate access to their medical records and current health status, and lifestyle and habit information might be available online for verification in digital format. If consumers have an intimate knowledge of their mortality risk, they might even be able to do their own risk assessments online using company or specialist insurance services. Instead of going through the underwriting process as we know it today, an applicant could be assessed immediately by making his or her personal risk data available upon application delivery, or the judgment predicated on the outcome of an independent risk assessment.
With the advent of wearable sensors, a few adventurous insurers have begun dabbling with the concept of dynamic underwriting, a framework that allows premiums to be adjusted throughout the life of a policy based on an individual’s risk profile over time (i.e., reduced or increased as a policyholder’s risk profile changes). At present, dynamic underwriting is focused more on using wellness initiatives aimed at improving health via lifestyle to strengthen customer engagement and promote policyholder satisfaction.
In the future, greater access to data could let insurers help policyholders better understand their medical histories, control their conditions, and adhere to medications to improve prognosis. As objective risk data becomes more readily accessible to insurers, this trend is likely to continue and expand.
AI: the biggest event in human history?
In 2016, at the launch of the Leverhulme Centre for the Future of Intelligence in Cambridge, U.K., the late Stephen Hawking, physicist, cosmologist, and author, said: “Success in creating AI could be the biggest event in the history of our civilization. But it could also be the last—unless we learn how to avoid the risks.”[7]
Used correctly and trained with the right data, AI can help remove human bias and add objectivity to underwriting decisions. It enables expert systems to rapidly and repeatedly take in and process large quantities of data—quantities beyond the capabilities of any individual human underwriter. Nevertheless, chief underwriters will need to ensure their teams retain final authority.
While Big Data promises to boost both productivity and consumer convenience, it is essential to also recognize the potential harm AI could bring about, such as lack of transparency, loss of control, and unintended expression of hidden biases. Already, in law and order, politics, and social media, several high-profile instances have occurred where data science has caused human suffering, gross injustice, and associated reputational damage. Obviously, with such high stakes, it is imperative insurers comply with all regulatory controls and maintain the highest level of ethical integrity.
In addition, as the use of AI and data-driven decision-making expands, it will become increasingly important for underwriters to remain vigilant in ensuring the safe and fair use of personal data. The insurance industry has long experience in ensuring data privacy and security. Insurers understand that building customer trust is essential, and that transparency and openness are vital ingredients to motivating brand loyalty and maintaining trust.[8]
It is important to remember, however, that AI algorithms cannot reason as humans do; they are only as good as the data from which they learn.[9] For example, a commercially approved DL algorithm for melanoma diagnosis was recently shown to have produced an abundance of false positives. The algorithm was shown to be significantly influenced by surgical skin markings, and a high proportion of markings in melanoma-positive training images posited as the reason.[10] The long-term objective has to be a future where Big Data tools and underwriters work together seamlessly to make the best decisions.
Leveraging the science and art of underwriting
In an environment where machines and underwriters can work together, it is important to acknowledge that underwriting is both a science and an art.
With more opportunities for automation, underwriters should keep in mind the complexity of mortality and morbidity risk assessment. Underwriting guidelines and calculators can sometimes make the process appear deceptively simple. But every individual is unique, and many cases do not fit neatly into specific risk categories. Skill and experience are often required to resolve conflicting medical evidence, fill in the gaps when the data is incomplete, and read between the lines to detect antiselection or fraud.
Looking beyond assessment of individual cases, it is also important to recognize the continuing need to take into account the broader picture. Data science cannot be expected to consider the full nature of the changing competitive environment, future mortality improvements, customer expectations, the needs of insurance agents and doctors, and ever-increasing demands for transparency. Clearly, Big Data by itself cannot be the solution; actuarial, medical, and underwriting expertise, supported by business acumen, will need to guide how, where, and when to use Big Data. Insurers that can leverage both the science and art of underwriting will be best positioned for the future.
Big Data’s implications for underwriting
A key priority for life and health insurers is to identify genuine opportunities for Big Data in underwriting to ensure efforts are focused on realistic ventures. Given the pace at which data science is advancing, it is essential for insurers to make sure the path taken aligns with the company’s overall strategy and plan. Also, as with any fast-developing technology, it is important to balance benefits against potential harms.
Implementing AI technologies and integrating a Big Data strategy is and will continue to be challenging. For every successful accomplishment, there will be failures. Resolute persistence is required to ensure new initiatives do not fail at the first hurdle, while recognizing the need to “fail fast” as needed. One critical aspect may be to define a clear framework for liability if underwriting decisions are outsourced to third-party AI technology.[11]
The future of underwriting is not yet written
Big Data can unquestionably enable better underwriting, but AI alone cannot change an organization or the insurance industry. In the near future, targeted innovations grounded in data science that will improve existing underwriting processes will undoubtedly be seen. In the longer term, however, a top-to-bottom overhauling of underwriting, if not the entire insurance value chain, could result.
Advances in technology coupled with Big Data techniques offer the promise of significantly lowering life insurer costs, which could improve affordability and widen life insurance product appeal. Ultimately, underwriters will need to evolve and adapt to an increasingly automated world, where human judgment and empathy can be augmented rather than replaced by artificial intelligence.
SCOTT RUSHING, MAAA, FSA, is head of global research at RGA Reinsurance Company. RICHARD RUSSELL, Ph.D., is lead health data scientist at RGA UK Services. YUNUS PIPERDY, BSc, FCII, is head of underwriting innovation at RGA UK Services.
References
[1] Cherowbrier J. Share of people using internet banking in Great Britain 2007-2019. Statista. 2019 Sep 16. www.statista.com/statistics/286273/internet-banking-penetration-in-great-britain/ [2] Rajkomar A, et al. Machine Learning in Medicine. NEJM. 2019. 380:1347-58. https://www.nejm.org/doi/full/10.1056/NEJMra1814259 [3] Fujisawa Y, et al. The Possibility of Deep Learning-Based, Computer-Aided Skin Tumor Classifiers. Frontiers in Medicine. 2019. 6: 191. https://www.ncbi.nlm.nih.gov/pmc/articles/PMC6719629/ [4] Lineaweaver N. Google’s new patent application highlights its interest in hospital software. Business Insider. 2019 Feb 6. https://www.businessinsider.com/google-patent-hints-electronic-health-record-market-plans-2019-2 [5] Bresnick J. Google Tries to Patent Healthcare Deep Learning, EHR Analytics. Health IT Analytics. 2019 Feb 5. https://healthitanalytics.com/news/google-tries-to-patent-healthcare-deep-learning-ehr-analytics [6] Terry K. Apple Opens iPhone EHR Feature to All Healthcare Organizations. Medscape. 2019 July 3. https://www.medscape.com/viewarticle/915208 [7] Hawking S. 2016. https://www.cam.ac.uk/research/news/the-best-or-worst-thing-to-happen-to-humanity-stephen-hawking-launches-centre-for-the-future-of [8] Banthorpe P. Trust Us? Innovation, Transparency, and Trust in the New Age of Digital Insurance. RGA. 2019 July 5. https://www.rgare.com/knowledge-center/media/articles/trust-us-innovation-transparency-and-trust-in-the-new-age-of-digital-insurance [9] Heaven D. Why deep-learning AIs are so easy to fool. 2019 Oct 9. https://www.nature.com/articles/d41586-019-03013-5 [10] Winkler J, et al. Association Between Surgical Skin Markings in Dermoscopic Images and Diagnostic Performance of a Deep Learning Convolutional Neural Network for Melanoma Recognition. JAMA Dermatology. 2019 Aug 14. 155(10): 1135-41. https://jamanetwork.com/journals/jamadermatology/article-abstract/2740808 [11] Falk M. Artificial Intelligence in the boardroom. Insight – Financial Conduct Authority (UK). 2019 Aug 1. https://www.fca.org.uk/insight/artificial-intelligence-boardroom

