
By Kurt J. Wrobel
“We need to make a data-driven decision.”
“We are not going to make a decision based on gut feel—we need data.”
“Without data, you’re just another person with an opinion.”
“Insights; insights; I want insights!”
These are statements that I’ve heard throughout my career, and they make sense.
Information is important to make decisions, and a large data set could be analyzed with sophisticated modeling to help improve decision-making. With the enormous amount of available data, however, it’s also easy to lose sight of the real goal behind data analytics—better decision-making and improved operational performance. Data can be an important building block for these goals, but it is not an end in itself.
The question is not whether data is useful, but rather to what extent it should be relied on when making a decision and how extensively it should be analyzed. It’s a question of degree, not a question of whether data should be used. In some cases, a decision or an operational change should completely rely on a sophisticated methodology to make the best possible decision. In other cases, an approach that simply follows the data could lead to poor decisions if qualitative information, operational considerations, the incentives of those analyzing the data, and holistic decision-making is not employed. In these cases, data and sophisticated modeling could be one element to improve decision-making but not the only factor.
This distinction will be the focus of this article—to what extent should we rely on sophisticated data analysis to make decisions broadly, and more specifically in a health care setting?
Defining the Building Blocks for Good Decision-Making
The building blocks for good data analysis are not complex. One needs data that are largely accurate, complete, and sufficient to answer the research question. The data analysis should be objective and free of any bias that will skew the conclusions of the analysis. And, finally, the analytic results should be rationally reviewed to produce a better decision or a plan to improve operating performance. These features would seem obvious and would hardly warrant an article. As highlighted below, though, while conceptually simple, the practical application of these principles is difficult and can lead to faulty conclusions if not properly managed.
The data may not meet the necessary requirement for accuracy, completeness, and sufficiency.
In many cases, the collected data are based on responses from individuals who have an incentive to report a biased opinion. While an analyst may never know the extent of this bias, she could make a value judgment on its likely accuracy—particularly if incentives could lead to biased results. For example, if data are collected consistently and the respondents do not have a financial or social incentive to change an observation, it will likely be more accurate than data collected inconsistently or where respondents have an incentive to be untruthful.
The purchasing behavior of consumers provides a clear example of when the data are likely to be accurate. Because a purchase represents a mutually agreed-upon financial transaction, the observed behavior is likely to be accurate simply because it reflects actual interests of the consumer. In contrast, a declared intention to vote for a candidate could be inaccurate because the respondent bears no economic cost for providing an untruthful answer.
In addition, a small data set could have insufficient information to make a reasonable projection, or the data could be a subset of the data that is not representative of the entire population. These problems are common occurrences that are too infrequently highlighted when conclusions are developed in a research study. Moreover, in many cases, the findings from these studies are given the same weight as conclusions from studies with much more robust data.
There exists the potential for biased findings or inappropriate analysis.
The problem with data analysis is that it has to be analyzed by people, and they have the potential to incorporate their own biases into the analysis. The potential for these biases should not be viewed as a minor problem to be overcome, but rather a significant issue that needs to be explicitly addressed. An entire discipline within economics—behavioral economics—focuses on these innate biases and how they impact rational analysis and decision-making. While the list of cognitive biases is long the potential for bias is particularly problematic if the results of a research study confer a financial benefit, enhance the renown of the author, or support a previously held position. People like positive stories about their own work or preferred policy position and they can go to great lengths to prove these stories with data.
With the advent of more data and improved software, this new environment has ensured that more people will review and draw conclusions from information. While this trend can lead to benefits, it has the unintended side effect that more and more analysis can be conducted with flawed methods that could be incorporated into the decision-making process.
The final work product is inappropriately used by decision-makers.
Even if the data are accurate and the analysis objective, the results of the study may not be used appropriately and could ultimately lead to less effective decision-making.
For example, if a careful data analysis produces a simplified metric to track a business result, a decision-maker may choose to completely rely on the quantitative result without considering qualitative factors in the decision and ignore the potential uncertainty of the conclusion. The end result could be worse than a decision solely based on qualitative factors.
Several other problems also exist:
- Quantitative analysis could be overemphasized to justify significant data infrastructure spending.
- Unwarranted risk-taking could be encouraged by recent historical success in using an analytical approach.
- Key initiatives could be given insufficient attention if the data are used to focus effort on too many projects.
In my view, the problems highlighted above should not be viewed as hypothetical concerns that occasionally occur in practice. I think these problems are seen throughout a large proportion of analytic work. The data could be wrong; the analysis biased or poor; and the results of a study misused. If these problems exist, the benefits of a careful analysis using data and sophisticated modeling will be diminished or even prove counterproductive in improving decisions.
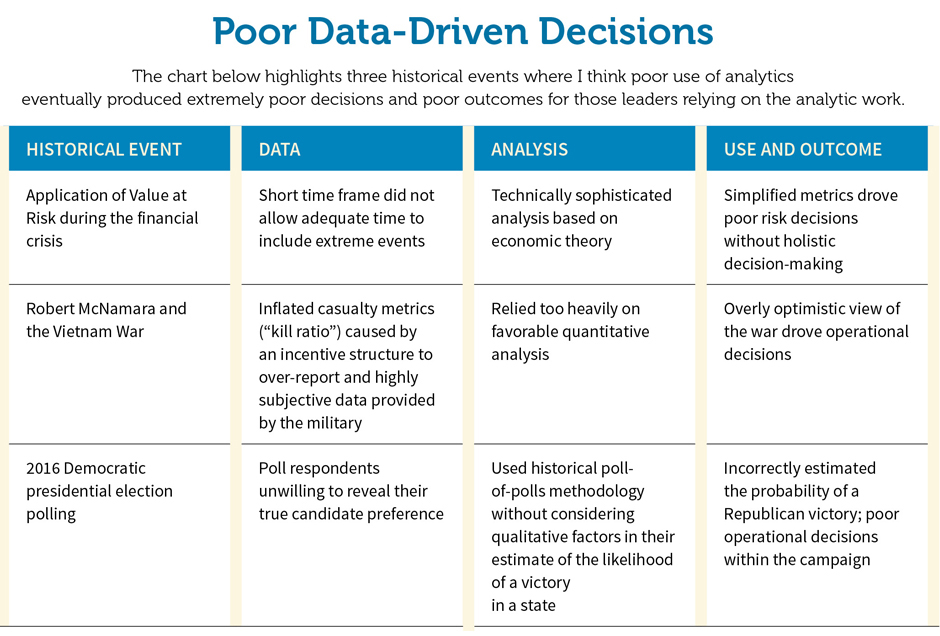
The attached sidebar (“Poor Data-Driven Decisions”) highlights several historical case studies where I believe poor analysis led to poor decisions and ultimately failure. By highlighting these decisions, the case studies provide an important lesson on the overreliance of data and can help counter the many stories about the successes of using data.

When Data Analysis Is Most Useful
The typical Big Data approach provides a concrete example of when sophisticated data analysis is most useful and should be the key driver in making operational decisions. In these approaches employed by Amazon, Google, Walmart, Target, and many other successful companies, analysts use significant real-time data to develop algorithms to better present web links or product information either online or in a store.
- By using consistently collected information where the behavior is based on actual purchases, the data will likely be free of bias, accurate, and substantial. The robustness of this data ensures that the underlying data can more likely be relied upon when developing conclusions.
- This approach also benefits from being developed from a simple system (buy or not buy, for example) where the purchasing behavior is unlikely to change in a short time period. In this stable system where the purchasing behavior is unlikely to change in a short time frame, the analysis will be much more likely to produce an accurate result. The opposite, of course, applies for projections where the underlying system is changing and the potential outcomes widely divergent. The estimates, in such a case, are much less likely to be accurate.
As an illustration, using the same purchasing behavior example, the data and the conclusions drawn from this data would be much less useful if a serious economic crisis has just occurred and the purchasing behavior of consumers has changed. In this case, the changing environment has made the historical information less useful and the original conclusions much less accurate.
- With the constant influx of new information, the model can be improved and provide an immediate feedback loop that will guide improvements in the model and avoid a misguided bias toward a particular result. In this situation, biases will likely be corrected by simple trial and error. This approach also has the added benefit that causation and correlation are much less important because any mistakes will likely be fixed in later iterations.
- The operational impact of the analytic findings is also clear—continuously refine the presentation of the web views or products to the end consumer. The operational decisions are also made easier because the cost of mistakes is relatively low.
The Big Data special case highlighting sophisticated data analysis illustrates the promise of extensively using data to answer business questions. This approach is a very special case, however. If the features in the special case do not exist, simply following the data and using sophisticated data analysis may not be appropriate to improve the decision-making process.
Applications to Health Care Analytics
With a wide range of data and potential applications, health care provides excellent case studies that illustrate where data should be extensively used—and where it shouldn’t.
Targeting activities—identifying claims fraud and members with more extensive treatment needs. These targeting activities most resemble the special Big Data case discussed above and represent the best opportunity for more sophisticated analysis. The data are accurate and largely free from bias, a large number of observations are available, the data can be used immediately, and the underlying system is relatively stable over a short period of time. In addition, because the identification process can provide immediate feedback on its success, the potential for any bias is limited. The decision-making process is also simple—the decision to investigate fraud or initiate medical management can be used to better allocate resources relative to a less-optimized system. Data, in this case, is extremely useful and the real-time information has the potential to improve operational performance.
Benchmarking—including information on the health plan level and individual practice patterns. The benchmarks produced by actuarial consulting firms identify a health plan’s performance relative to comparable health plans. Similar to the targeting activities described above, these benchmarks can serve as the starting point for additional operational focus.
For example, if a health plan finds its inpatient utilization higher than other health plans, this information can be used to develop operational plans to improve performance. A more favorable result in another category of service may also suggest fewer improvement opportunities and the potential to focus efforts in areas with the most significant performance disparity.
Prospective risk-taking (rate setting). While in the preceding health care applications the data and the associated analysis were essential, the data used in rate setting is important but just one element of many in developing the best possible decision.
Fortunately, in most rate-setting studies the data are accurate and usually sufficiently credible to develop rates. In addition, the historical performance is likely to be an important indicator of future performance. The professionalism among actuaries also helps ensure that the analysis will be less likely impacted by bias.
Relative to the Big Data analysis, however, the analysis is much more difficult because the projection period is much longer and the continual refinement allowed in other models is not possible when a single rate filing is required for the entire year. In addition, the infrequent decisions required under rate setting can involve high-stakes financial plays that could have a significant impact on an organization. In this environment, simply running the data with a Big Data approach will likely be inadequate.
Unlike the targeting approaches discussed above, an actuary needs to have a more holistic decision-making process with senior management to ensure broad understanding of the underlying assumptions and the potential volatility associated with the final premium or capitation rate. The management team also needs to take into account the broader strategy of the organization and consider the potential downside if the projections are significantly different than expected. Qualitative considerations also need to be made about an organization’s ability to impact utilization and negotiate favorable provider contracts.
As the data becomes less useful, the underlying model should be relied upon less and other operational concerns should become paramount—including the ability for an organization to withstand negative results. When rates were developed for the 2014 Affordable Care Act rate filing, for example, insurers did not have historical experience in a program undergoing unprecedented change in eligibility rules and economic incentives to purchase insurance. In this special case, a broader review of the risk and general intuition was important to augment any detailed analysis.
These distinctions are very important and should drive the thinking toward a business decision. If the rate-setting process will likely produce accurate results, the point estimate of the expected health care costs can drive the decision. If it is likely to produce a highly variable result, qualitative considerations regarding the financial risk will be paramount.
This same thought process can also apply for risk arrangements where the rates are based on relatively small number of observations. A highly uncertain environment should lead decision-makers to consider both quantitative results as well as qualitative considerations.
Return-on-investment studies. In order to support a financial investment, an analyst will usually develop a return on investment estimate to support the proposed project. These estimates typically have two key problems—the objectivity of those doing the analysis and the problem of developing an adequate control group. As suggested throughout this article, if people have an incentive to show a result, the final conclusions could be inaccurate, either knowingly or unknowingly, by virtue of these incentives.
The control group challenge is also a pervasive problem in health insurance. If an analyst estimates the results of a treatment where individuals self-selected into the program, a comparison between the treatment group and all others will almost certainly be biased. As a simple example, if people self-select into an exercise program, the health of those in the treatment group will almost certainly be better and see greater improvement.
Similar to many concepts in this article, while these problems may seem obvious, many organizations still make mistakes regarding them. And, even if the problem is acknowledged, the findings from studies like this could still be given inordinate weight relative to well-constructed analysis.
Despite these potential problems, an analysis measuring the relative effectiveness of a program is important for any organization. Because of the problems described above, leaders should create an environment to help ensure the objectivity of the analysis and look to use several different data sources to develop a conclusion on a program.
Academic studies. Academic studies have one unique feature that distinguish them from applied studies conducted within a company or a government agency: In order to be published and advance in one’s career, the findings must produce an interesting finding that advances the profession. This feature, at times, can lead to biased findings that should not be relied upon when making decisions. While the academic peer review process is designed to catch these shortcomings, the process is not perfect.
Research studies can take on many shapes and forms, but one type of study best illustrates an example where data is much less useful—infant mortality studies based on data from the Organisation for Economic Co-operation and Development. These studies run the gauntlet with problems: The data are collected in an inconsistent fashion, the sample size is relatively small; immediate feedback on the accuracy of the predictions may not be possible; and the results can be easily manipulated by changing explanatory variables in the linear regression. Moreover, the results could be influenced by the researcher’s political persuasion.
To better highlight the problem, the following discussion highlights an area of research that best exemplifies this problem with biased analysis—comparisons of country-specific health systems based on health outcomes. This research focus has long interested economists and other researchers who seek to explain health outcome differences among different countries.
While the data and methods vary, the research usually involves comparing an outcome (infant mortality, for example) over several countries with several variables that could explain the outcome—without assuming a specific treatment that could be driving the result. In much of this research, the research results will highlight the United States as an outlier with greater expenditure (as a percentage of GDP) and worse results (higher infant mortality, for example) and then suggest various policy solutions to help improve its position.

This research is instructive because it highlights all four elements of a research study that should be avoided:
Data from disparate sources with an inconsistent data-collection process. As highlighted in many research studies, the data collection methods, the definition of specific outcomes, and the measurement of such outcomes can vary widely among different countries. Instead of using data reported by health care professionals with strict definitions in a consistent manner, some countries use surveys and family-reported data with definitions that are not uniformly applied across all countries. The data can be further impacted by the extent of the medical treatment—with those countries with aggressive medical practices for costly conditions reporting results differently than other countries.
Limited data. The research is often focused on a limited number of actual data to perform the actual analysis. In many cases, the research focus is largely dependent on outcomes from the United States using fewer than 50 data points.[1]
Attempts to explain the expected outcome of a complex system over an extended period of time. The causal factors contributing to a health outcome could include everything from diet, lifestyle choices, genetic factors, income, education, culture, along with the country’s health system and financing. Although some of these factors can be controlled for in the research, it still remains extremely difficult to reliably control for these factors over several countries and account for all the factors that could contribute to a particular outcome.
A politically charged question where a definitive answer to the research will not ever be known with any degree of accuracy. Because an experiment cannot be developed to directly compare one health care system with a population from another country, a true definitive answer to the research is simply not possible. Without a clear definitive conclusion, this research has limited use and it is much more likely to lead the researcher to develop a conclusion consistent with her preconceived expectation.
While this research focus may not be appropriate to rely upon for important business decisions, I am confident that many in health care would find the topic interesting. The differences in how care is delivered and financed and how it impacts outcomes can make for an interesting philosophical discussion, but the techniques should not be a primary determinant used for real-life decision-making.[2]
Conclusion
The term “Big Data” has become an often-used phrase to describe the use of large data sets and sophisticated modeling to improve targeting of consumers and websites in a variety of different environments. As seen in the success of many of its advocates, it has been impactful in improving the operational performance among the most successful companies in our economy. The approaches used in these analyses are a special case, however, and not necessarily applicable with other business questions.
When the data is likely to be less accurate or insufficient, we need to look for other data sources and approaches to improve the decision-making process. If the projection period is long and continuous feedback unavailable, we need to set wider ranges for results and ensure that a process is developed. Most important, we need to incorporate holistic considerations with data to make better decisions.
In most analytic work in health care and other industries, the game is not just a mastery of technical models and Big Data, but a much more complex and methodical process that incorporates intuition, wisdom, and detection skill to produce the best possible outcome.
Actuaries would be wise to use all resources available to them to navigate this new area—and the Academy’s monograph Big Data and the Role of the Actuary,[3] released in 2018, offers a framework for considering professionalism implications of Big Data techniques. Well-written and accessible, the monograph should be required reading for any actuary engaging in this arena.
KURT J. WROBEL is chief financial officer and chief actuary at the Geisinger Health Plan.
References
[1] Scott Atlas; In Excellent Health: Setting the Record Straight on America’s Health Care; Hoover Institute; 2011.
[2] Kurt Wrobel; “Deciding what to research: How to spot and avoid bias”; Predictive Analytics and Futurism; December 2016.
[3] Available at http://www.actuary.org/BigData.pdf.


